Вопросы и задания
1. На чем основывается возможность двоичного кодирования текстовой информации?
2. На основании чего можно утверждать, что для латинских букв применяется семибитовое кодирование?
3. Зная, что в кодировке ASCII десятичный код каждой строчной латинской буквы на 32 больше кода соответствующей прописной буквы, представьте фрагмент этой кодировочной таблицы в формате, основанном на шестнадцатеричной системе счисления:
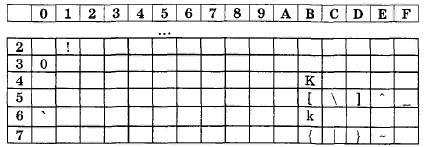
4. Используя результат выполнения предыдущего задания, декодируйте следующее сообщение, записанное в восьмибитовой кодировке:
01010101 01110000 00100000 00100110 00100000 01000100 01101111 01110111 01101110.
5. Определите вид кодировки и декодируйте следующие сообщения:
а) 235 207 212 197 204 216 206 201 203 207 215;
б) 213 224 244 244 236 224 237.
6. Петя и Коля пишут друг другу электронные письма. Однажды Петя отправил Коле письмо в кодировке Windows- 1251. Коля письмо получил, но прочитал его в кодировке КОИ-8. Получился бессмысленный текст, одно из предложений которого имело вид:
кЧАЮЪ ХМТНПЛЮЖХЪ ЛНФЕР АШРЭ ОПЕДЯРЮБКЕМЮ Я ОНЛНЫЭЧ ВХЯЕК. Какое предложение было в исходном сообщении?
7. Во сколько раз уменьшится информационный объем страницы текста при его преобразовании из кодировки Unicode (таблица кодировки содержит 65 536 символов) в кодировку Windows-1251 (таблица кодировки содержит 256 символов)?
8. Будут ли упорядочены по алфавиту фамилии, записанные русскими буквами, если их сортировку осуществить согласно кодам символов из кодировки Windows-1251?
9. Почему в кодировке ASCII сдвиг, с помощью которого по коду прописной английской буквы можно получить код соответствующей строчной, равен 32, а не, например, 26 (в кодировках КОИ-8 и Windows-1251 это же свойство сохраняется и для русских букв)?
Последнее изменение: Thursday, 17 January 2019, 14:30